【ElasticSearch】01-ElasticSearch使用

安装
Docker
IK分词器
分词器,就是将中文、英文拆分成多个词汇,包括单个汉字。
如:我爱玩手机,可以被分为:我、爱、玩、手机、玩手机五个词汇。
算法
IK分词器提供了两种算法:
1. ik_smart:最少切分。
2. ik_max_word:最细粒度划分。
安装
下载相应版本的ik分词器
https://github.com/medcl/elasticsearch-analysis-ik/tags;下载完毕之后,解压并放入到elasticsearch中plugins下的ik文件夹中。
重启elasticsearch。
使用Kibana测试
ik_smart、ik_max_word使用效果
使用
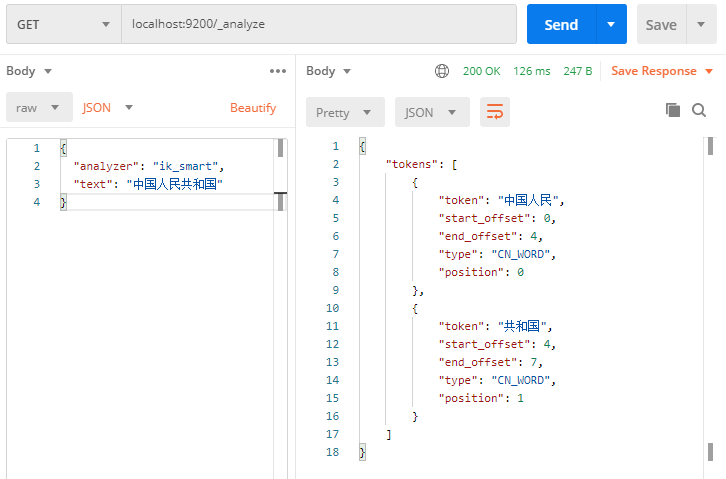
最粗粒度划分
1 | // 最粗粒度划分(zn-Ch) |
被划分为:’中国人民’, ‘共和国’ 两个词语
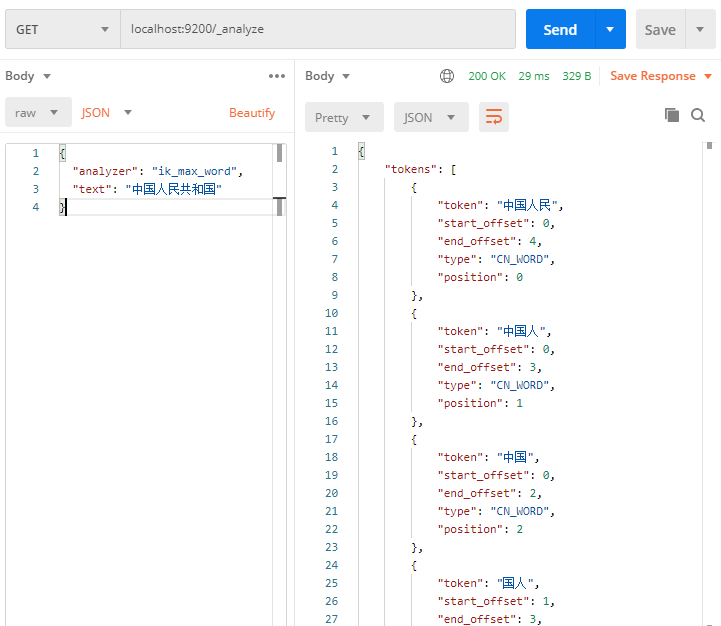
最细粒度划分
1 | // 最细粒度划分(zn-Ch) |
被划分为:’中国人民’, ‘中国人’, ‘中国’, ‘国人’, ‘人民共和国’, ‘人民’, ‘共和国’ 七个词语
扩展分词器
想要在分词其中添加没有的词汇。如:’举头望明月’。
未添加自定义分词器
1 | GET _analyze |
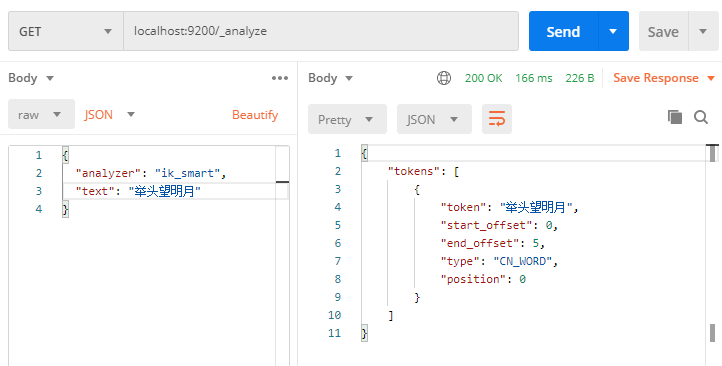
‘举头望明月’被分解为三个词:’举头’, ‘望’, ‘明月’
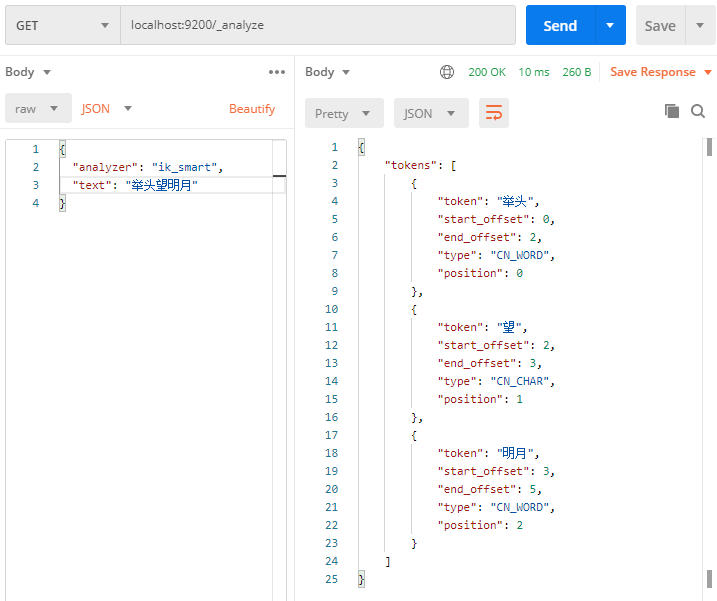
添加自定义分词器
打开
C/development/elasticsearch/elasticsearch-7.11.1/plugin/ik/config/文件夹。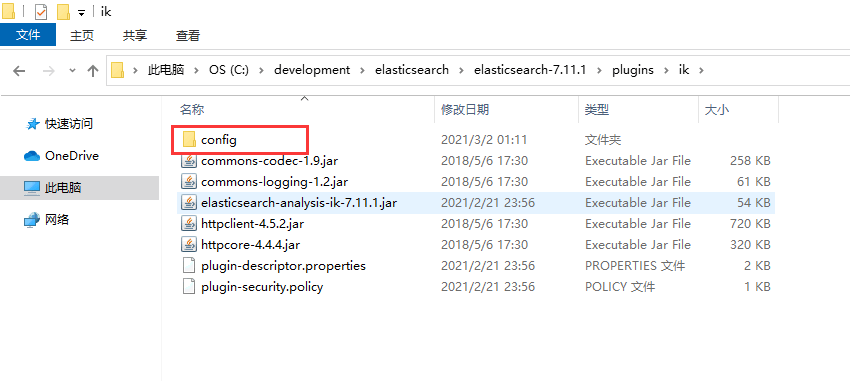
在该文件夹下创建自己的dic文件。
注意:最好复制已有的dic文件,将其修改。自己创建的dic文件可能因为格式问题无法被识别。
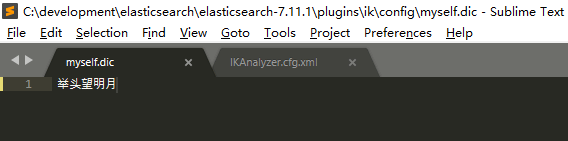
修改
IKAnalyzer.cfg.xml文件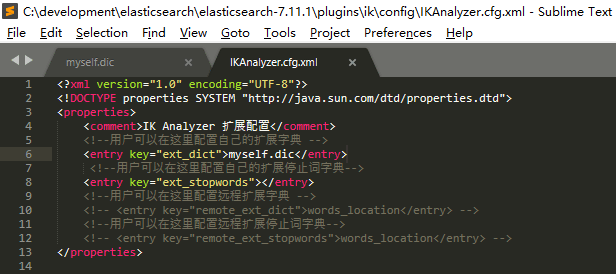
重启ElasticSearch,查看日志
创建的字典已经被加载到分词器中
再次解析“举头望明月”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17GET _analyze
{
"analyzer": "ik_smart",
"text": "举头望明月"
}
{
"tokens": [
{
"token": "举头望明月",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}
ElasticSearch基本操作
ElasticSearch,其增删改查操作完全遵循Restful风格。查询:GET;添加:POST;修改:PUT;删除:DELETE;
操作索引
查寻索引
查询索引信息GET /_cat/indices?v

添加索引
创建一个名为test的索引PUT /test/

删除索引
删除一个名为test的索引DELETE /test
删除所有索引DELETE /*

操作文档
文档类型几乎已被弃用,全都被
_doc所代替。
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随即文档id) |
| POST | localhost:9200/索引名称/_update/文档id | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
创建文档
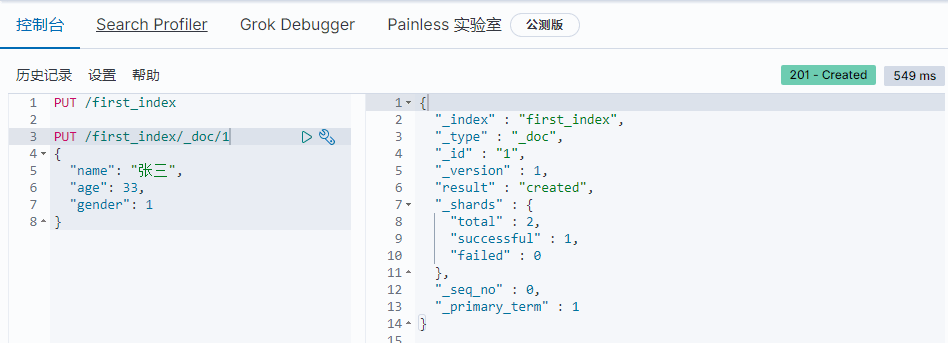
通过PUT方式
该方式创建必须指定id。
1 | //请求 |
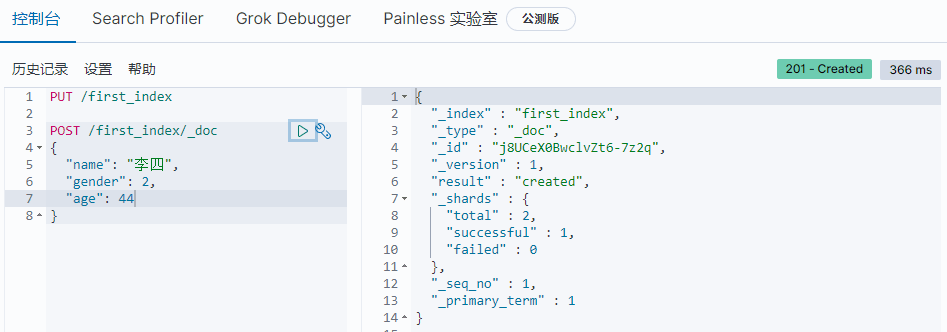
通过POST方式
该方式创建无需指定id,elasticsearch会为其自动创建一个字符串作为id;也可以向PUT请求一样指定id。
1 | POST /student/_doc |
修改文档
修改所有字段
该方法需要指定id,并覆盖指定id的所有数据
1 | PUT /student/_doc/1 |
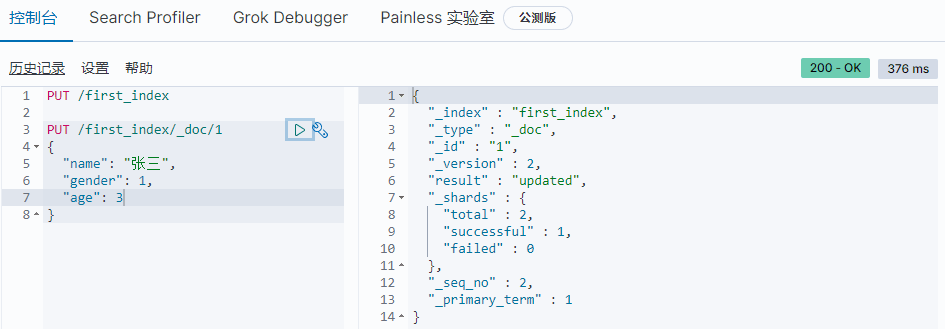
修改某些字段
对某一个文档进修改某些字段时使用。
1 | POST /student/_update/1 |
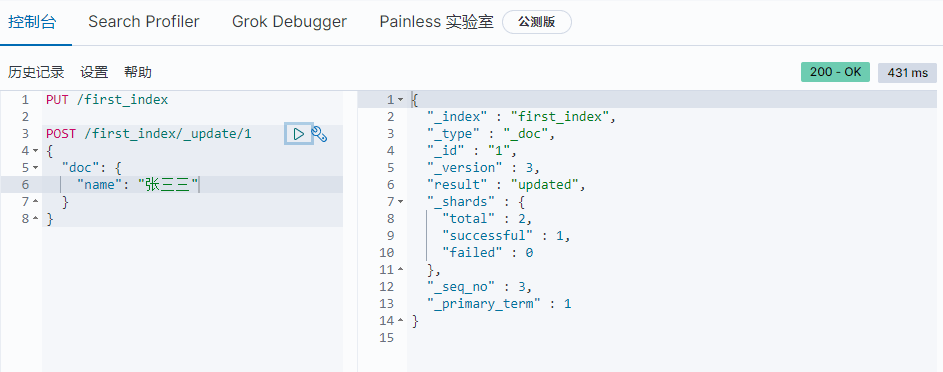
删除文档
删除文档
指定索引名称,id删除某个文档
1 | DELETE /first_index/_doc/1 |
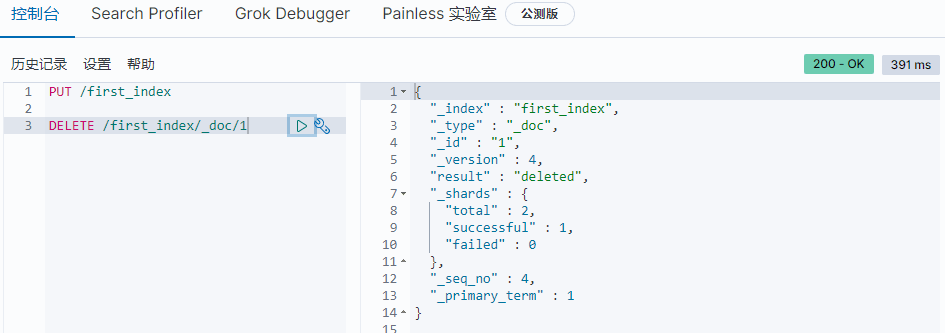
返回结果说明
| 字段 | 说明 | |
|---|---|---|
| version | 更新次数 | |
| result | 操作类型(update:更新,created:创建) | |
| score | 匹配度。如果分值越高,查询出的结果优先级越高 |
查询文档
使用first_index索引。先给这个索引插入一些数据,供后面查询使用
1 | //1 |
指定id查询
1 | GET /first_index/_doc/1 |
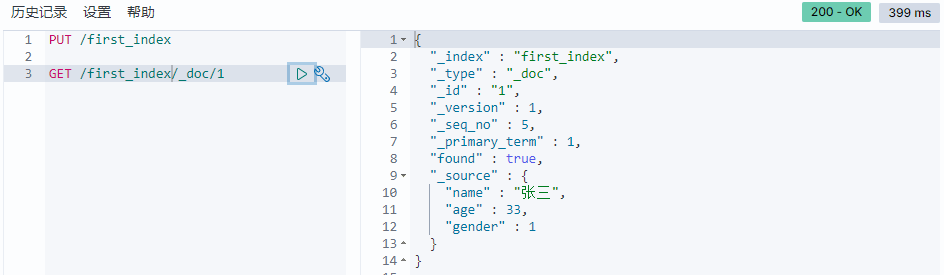
查询全部
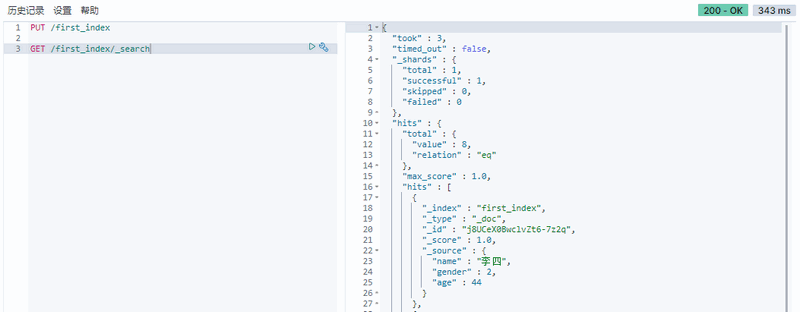
1 | GET /first_index/_search |
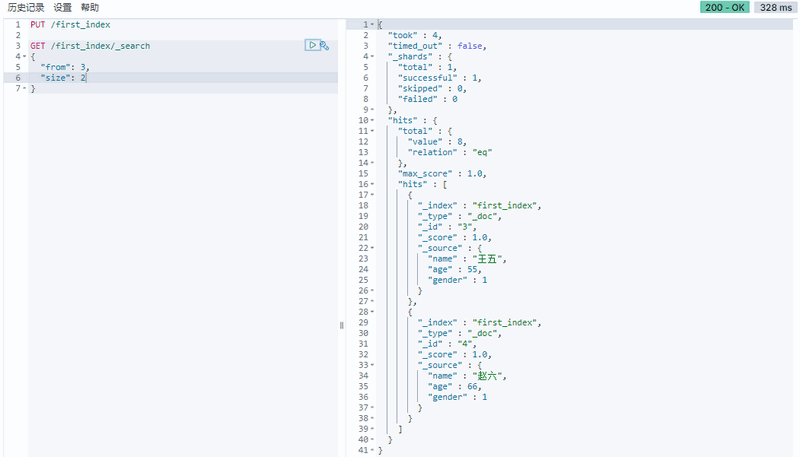
分页查询
from(偏移量), size 相当于MySQL的offset和limit
1 | GET /first_index/_search |
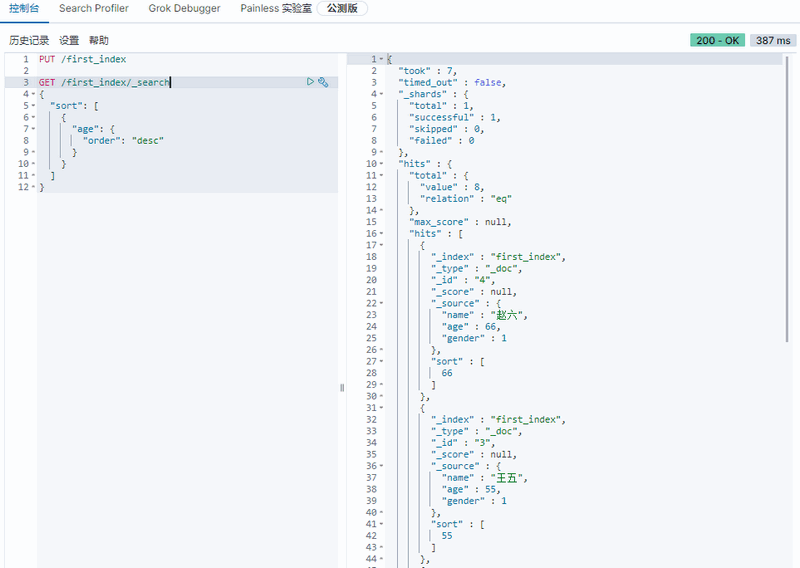
排序查询
sort键的value是一个数据,可以对多个字段进行排序
1 | GET /first_index/_search |
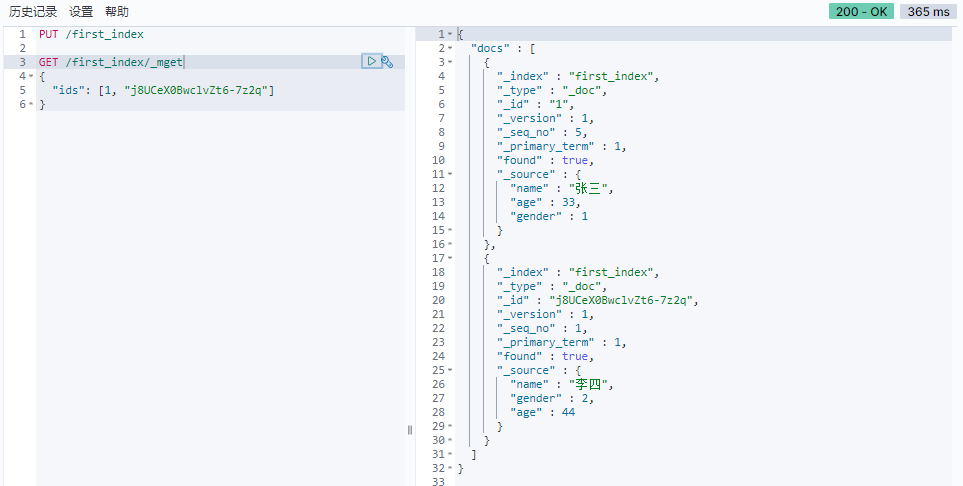
批量查询
1 | GET /first_index/_mget |
泛查询
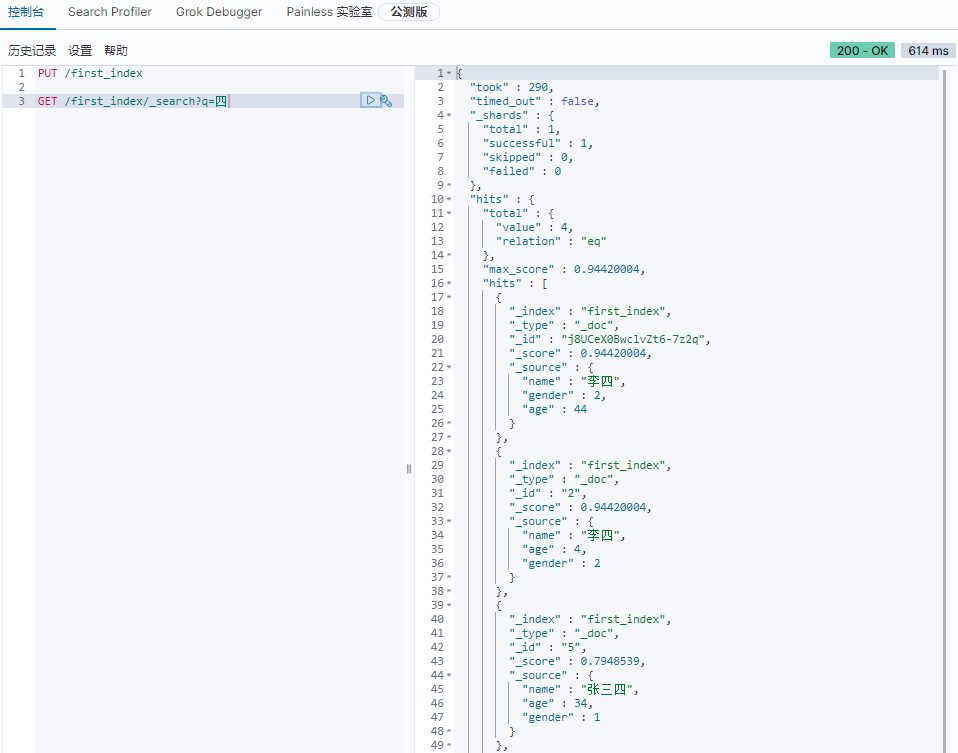
查询包含
四的数据这种方式查询不限制字段,可以是name,gender等其他字段,只要包含
四这个字,都可以被查询到1
GET /first_index/_search?q=四
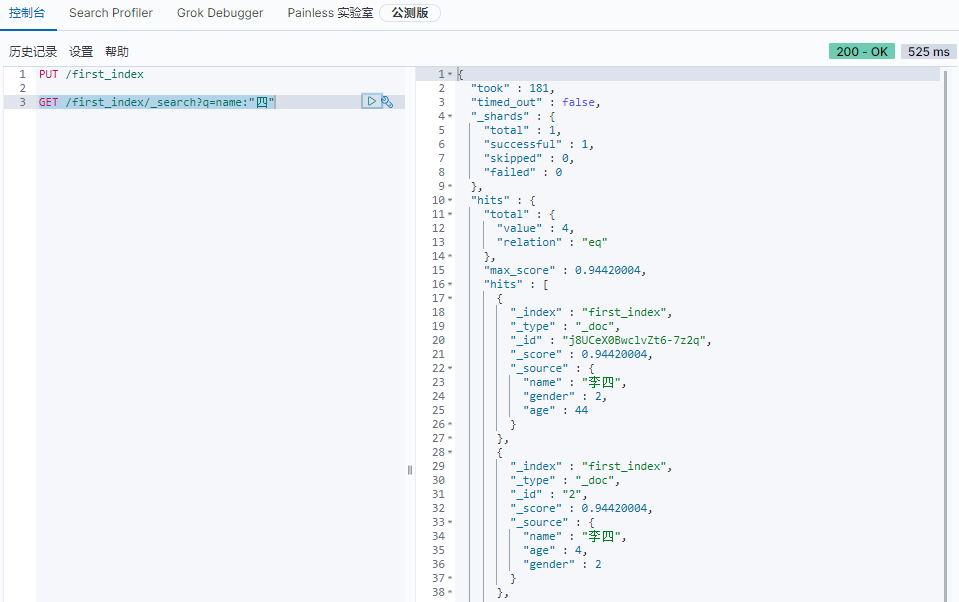
指定字段,查询包含
四的数据1
GET /first_index/_search?q=name:"四"
复杂查询
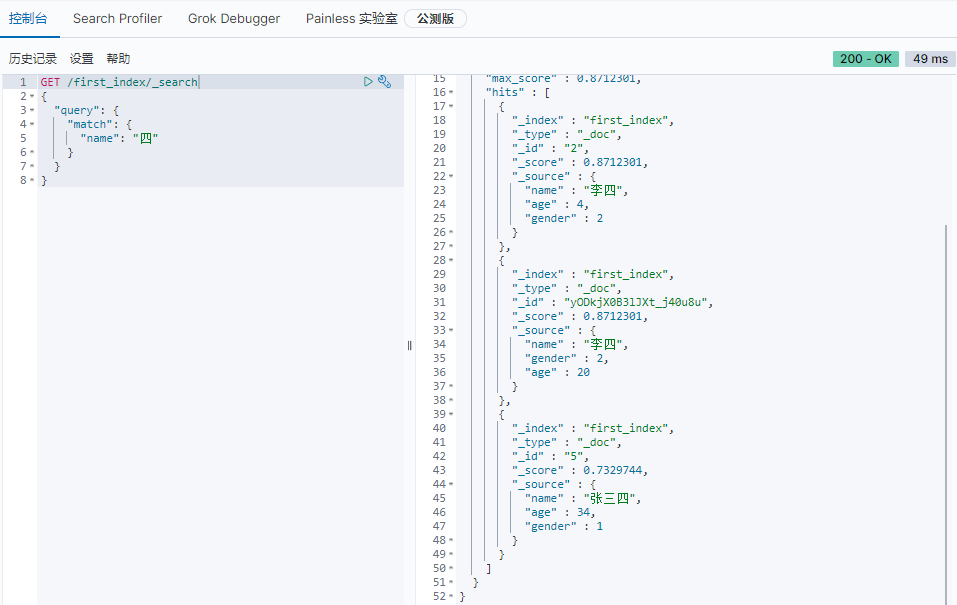
match
单条件查询
1
2
3
4
5
6
7
8GET /first_index/_search
{
"query": {
"match": {
"name": "四"
}
}
}
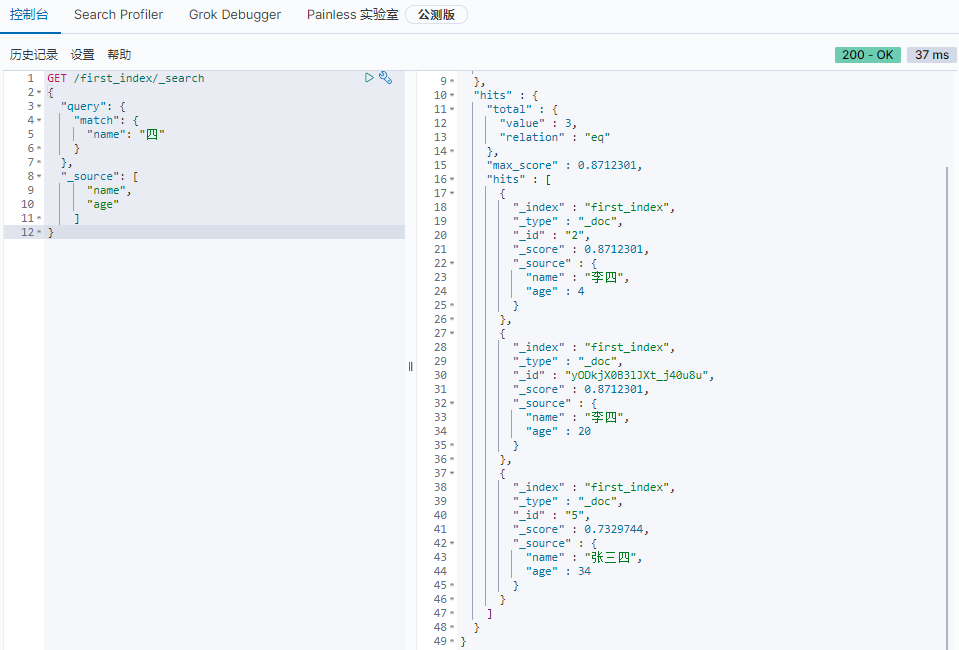
单条件查询、匹配字段
1
2
3
4
5
6
7
8
9
10
11
12GET /first_index/_search
{
"query": {
"match": {
"name": "四"
}
},
"_source": [
"name",
"age"
]
}
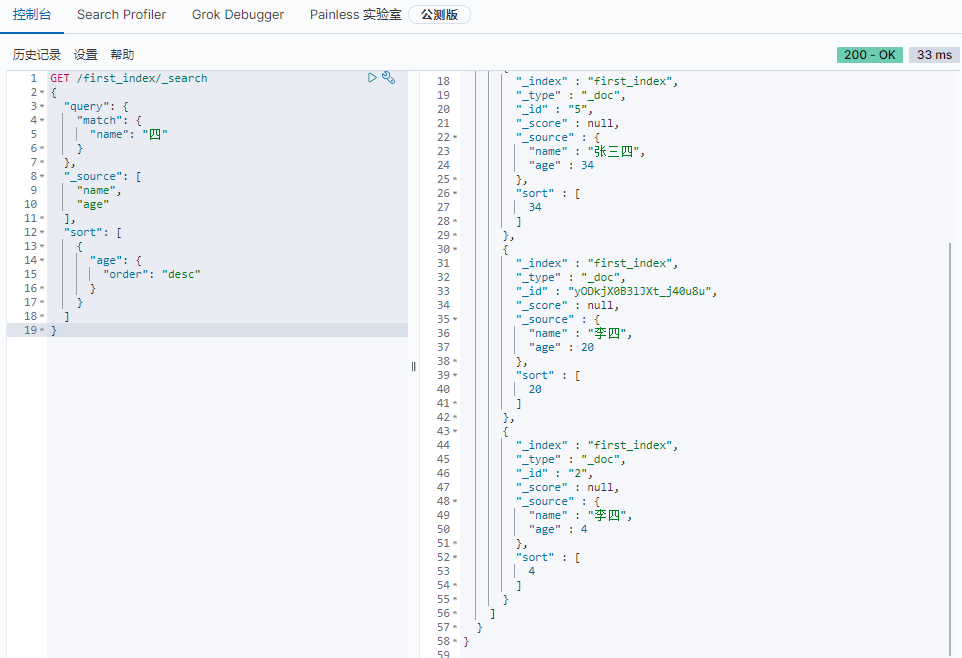
单条件查询、匹配字段、排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19GET /first_index/_search
{
"query": {
"match": {
"name": "四"
}
},
"_source": [
"name",
"age"
],
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
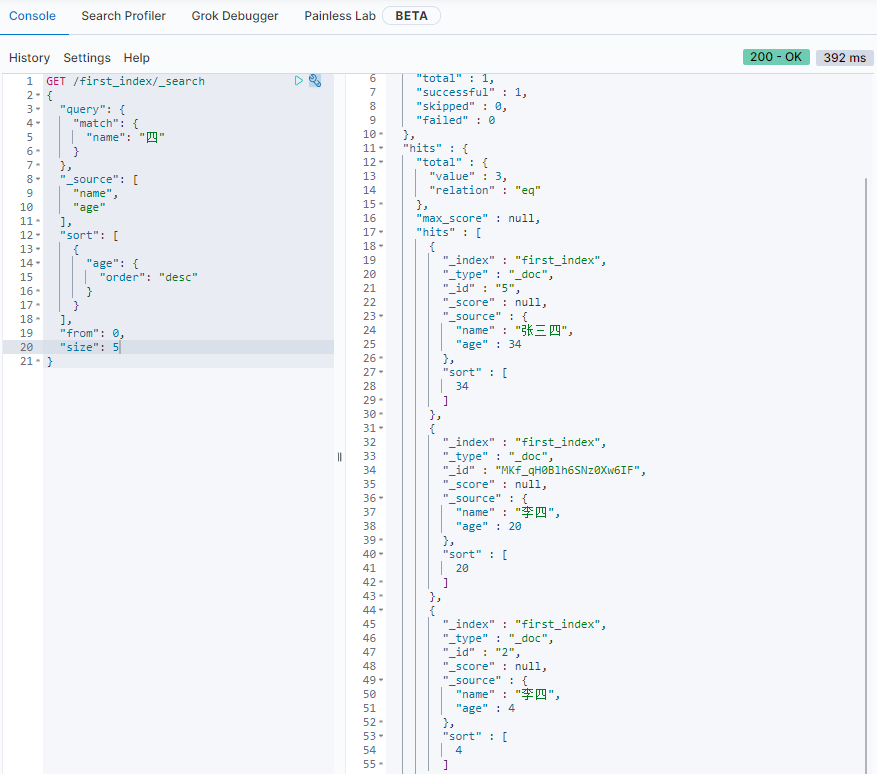
单条件查询、匹配字段、排序、分页
1
2
3
4
5
6
7GET /first_index/_search
{
"query": { "match": { "name": "四" } },
"_source": [ "name", "age" ],
"sort": [ { "age": { "order": "desc" } ],
"from": 0, "size": 5
}
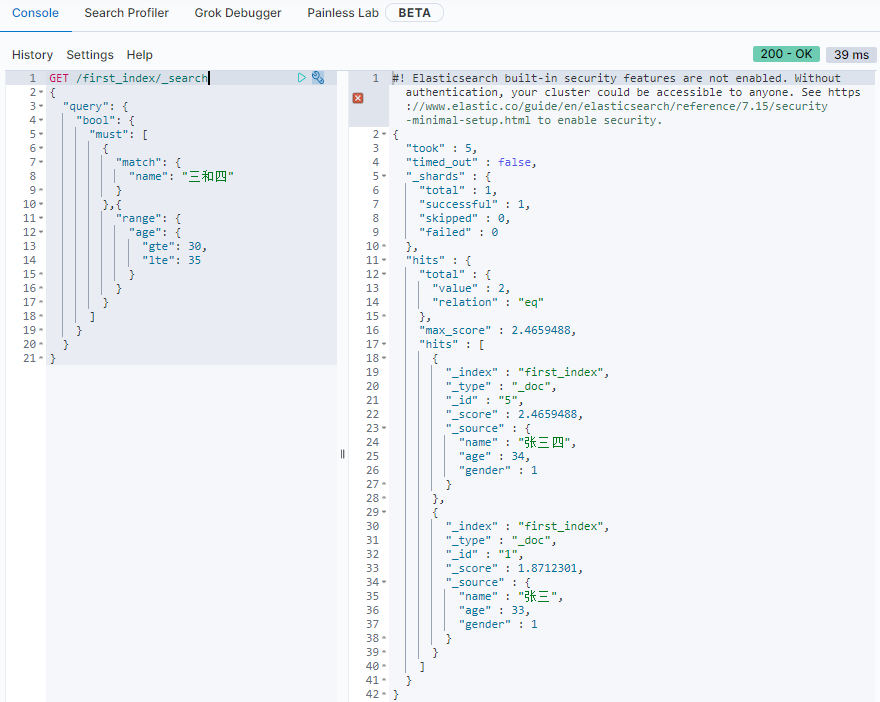
must
- name中包含
三,四 - age在[30, 40]范围内
1 | GET /first_index/_search |
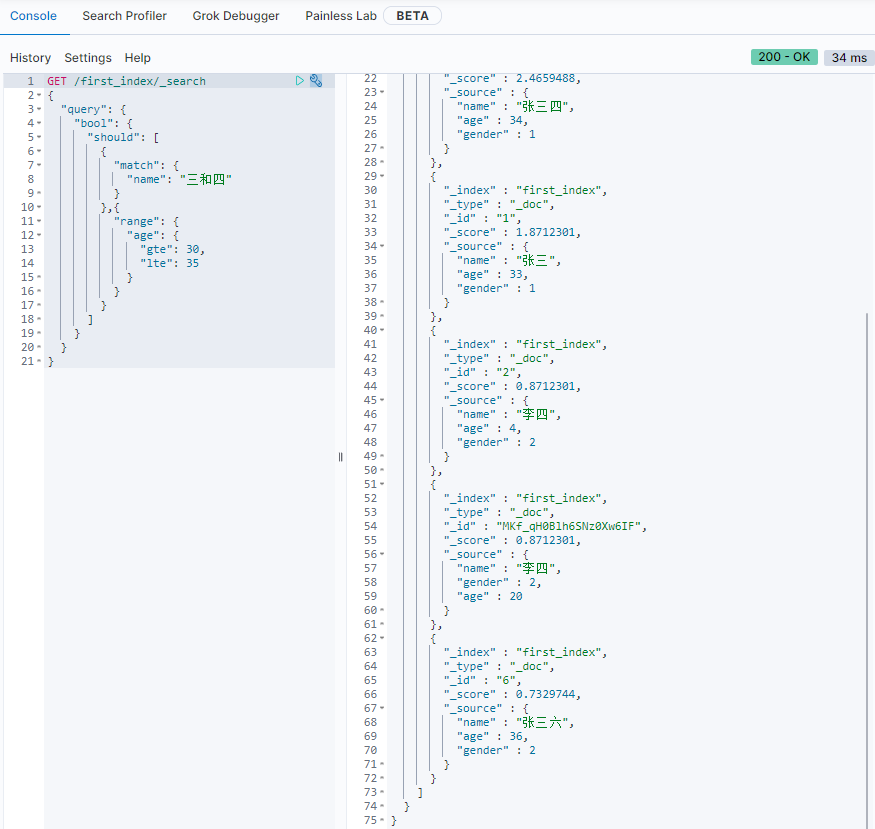
should
name中包含
三,四age在[30, 35]范围之间
1 | GET /first_index/_search |
must_not
- name中不包含
三,四 - age的范围不在[30, 35]之间
!(name.contails("三") || name.contails("四") || (age >= 30 && age <= 35))
1 | GET /first_index/_search |
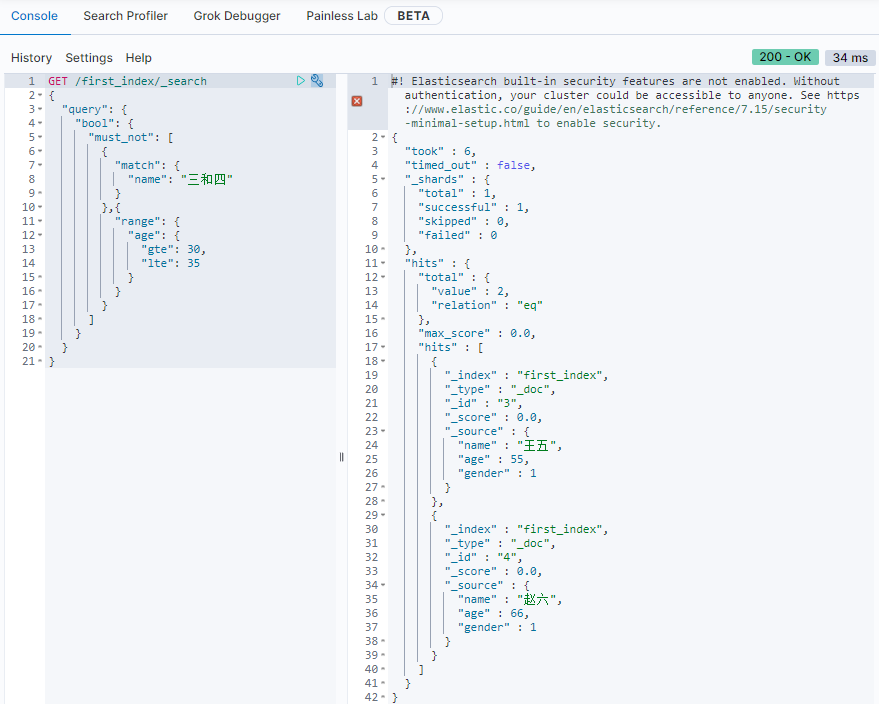
filter
- name中包含
三,四 - age在[30, 40]范围内
- 过滤掉age在[30, 33]范围内的数据
1 | GET /first_index/_search |
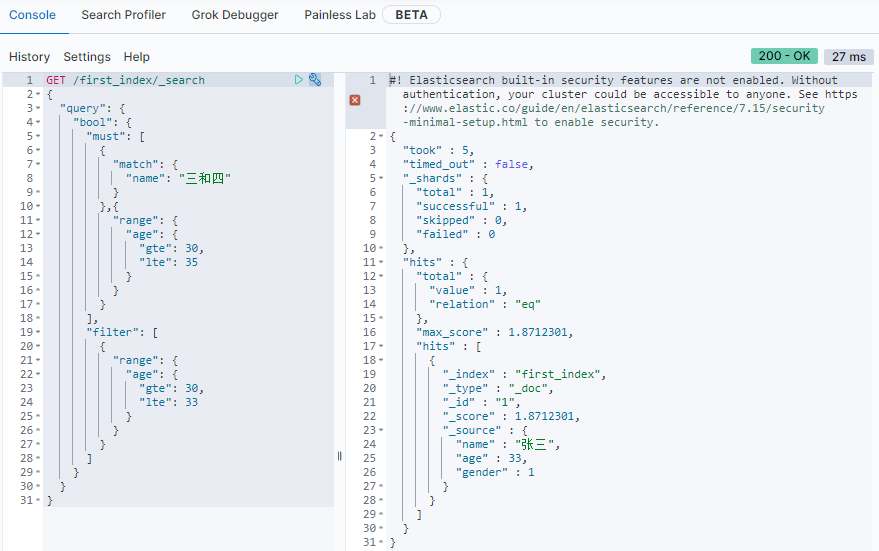
term
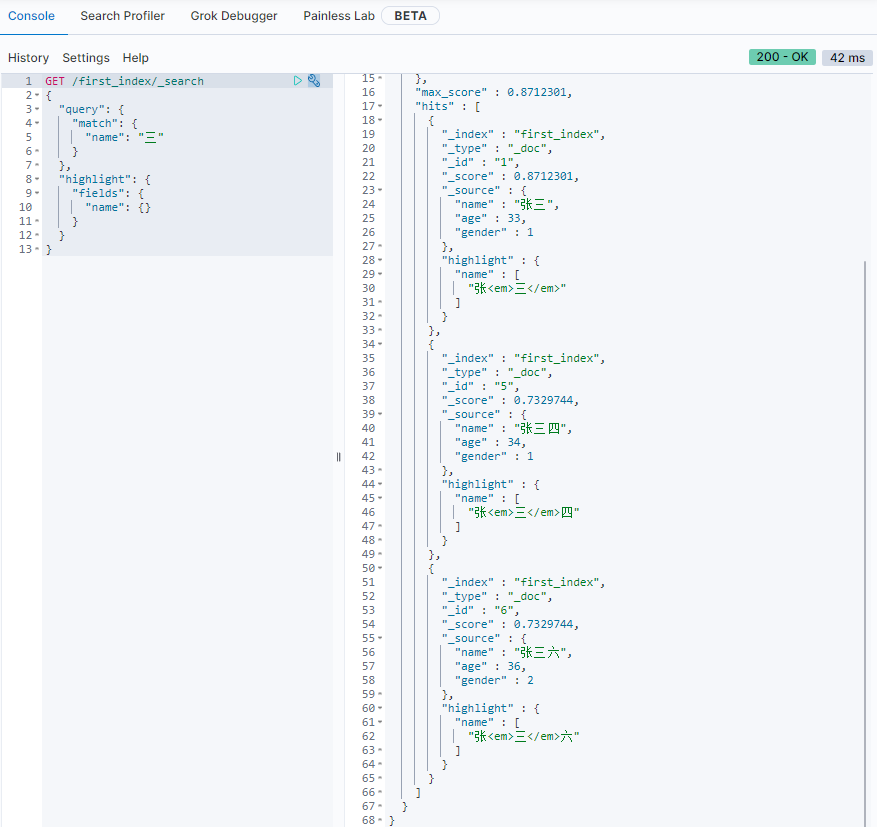
高亮
- 给name字段中的
三,添加高亮
1 | GET /first_index/_search |
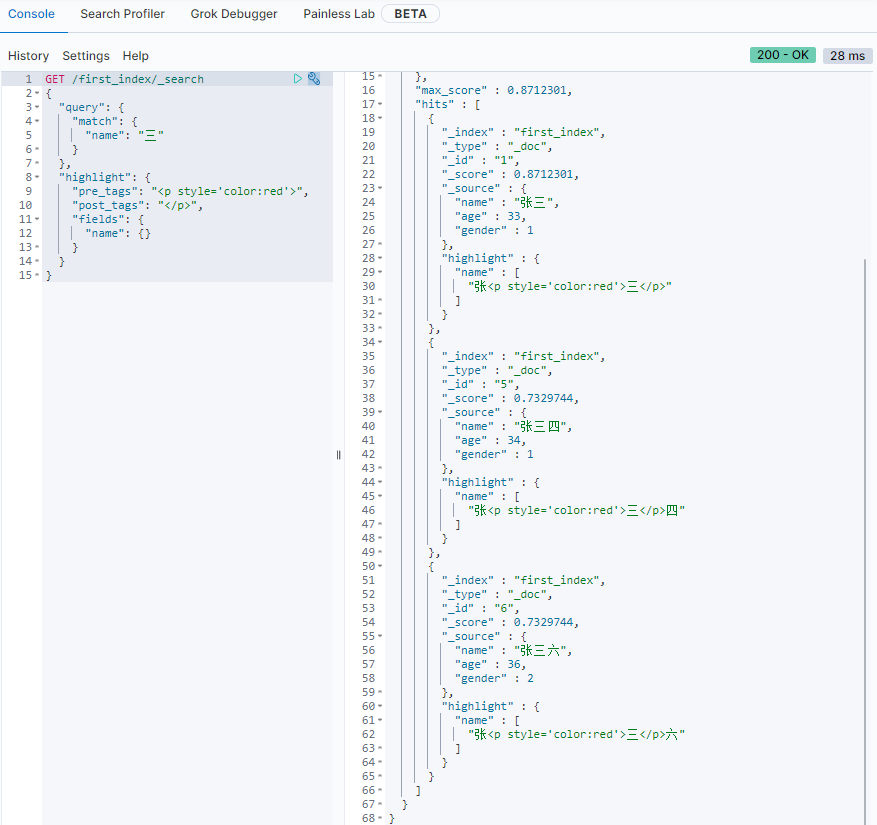
自定义标签
1 | GET /first_index/_search |
term:直接去查询,且该字段类型需为keyword。
match:会使用分词器进行查询。
两个类型
- text:会被分词器解析。
- keyword:不会被分词器解析。
返回结果说明
| 字段 | 说明 | |
|---|---|---|
| version | 更新次数 | |
| result | 操作类型(update:更新,created:创建) | |
| score | 匹配度。如果分值越高,查询出的结果优先级越高 | |
| hits | 索引和文档信息(结果总数、数据结果) |